진행하고 있는 사이드 프로젝트에서 HTTP Method 중 GET요청에 대해 최적화를 진행해봤다.
기존 코드는 Entity 간의 연관관계가 1 : N 이었고, 흔히 말하는 N+1문제가 발생했다.(N+1 문제는 유명하니 검색을 통해 알아보자!)
해결 방법
- Join Fetch
- EntityGraph
- Projection
나는 여기서 3. projection의 방법을 선택했다.
아무래도 DTO로 projection 하는것이 영속성 컨텍스트를 거치지않고 '비영속' 상태로 데이터를 얻을 수 있기 때문에 가장 속도가 빠르다.
선행 개념
영속성 컨텍스트?
먼저 ORM부터 알아보자. ORM(Object Relational Mapping)은 객체와 데이터베이스 테이블의 매핑을 통해 엔티티 클래스 객체 안에 포함된 정보를 테이블에 저장하는 기술이다.
JPA는 이러한 기술 중 하나 이며, 테이블과 매핑되는 엔티티 객체 정보를 영속성 컨텍스트를 통해 애플리케이션 내에서 오래 지속되도록 보관한다.
즉, 1차 캐시로써 활용된다는 뜻이다. 그래서 한 번 조회된 객체는 디스크에서 가져오는 것이 아니라 캐시로써 있는 영속성 컨텍스트에서 가져오므로 성능 상 이점이 있다.
DB
영속성 컨텍스트와 데이터 베이스의 관계는 어떨까?
- persist() : 엔티티를 영속성 컨텍스트에 저장
- detach() : 엔티티를 영속성 컨텍스트에서 분리
- remove() : 엔티티를 영속성 컨텍스트에서 삭제
- flush() : 엔티티를 영속성 컨텍스트 -> 데이터베이스에 반영
- commit() : flush()가 함께 발생하며, 트랜잭션의 변경 사항을 데이터베이스에 반영
- JPQL 쿼리 : 플러시 자동 호출
간단하게 메서드를 통해 어떻게 동작하는지 알아봤다. 그렇다면 무조건 영속성 컨텍스트를 거치지 않고 DTO로 조회하는게 좋을까? NO!
| 특징 | 네이티브 쿼리 DTO 조회 | 엔티티 조회 |
| 영속성 컨텍스트 포함 여부 | X | O |
| Dirty Checking 지원 | X | O |
| 캐싱 효과 | X | 1차 캐시 사용 |
| 조회 성능 | 대량 조회 시 유리 | 소량 조회 및 트랜잭션 관리에 유리 |
| 트랜잭션 종료 시 동기화 | X | 자동으로 DB와 동기화 |
각 상황에 맞춰서 쓸 줄 아는 법이 중요하다. 이번 포스팅에서 주제는 GET요청에 대한 것이므로 트랜잭션 관리 보다는 빠르게 조회만 하면 되니 DTO로 nativeQuery를 사용해서 조회해보겠다.
@Query(value = "SELECT v.id AS id, v.name AS name, u.nickname AS userName, " +
"t.team_name AS teamName, u.profile_image_url AS photoURL, " +
"DATE_FORMAT(v.date, '%Y-%m-%dT%H:%i') AS partyDate, v.latitude AS latitude, " +
"v.longitude AS longitude, v.location AS location, " +
"v.short_location AS shortLocation " +
"FROM viewing_party v " +
"JOIN users u ON v.user_id = u.id " +
"JOIN team t ON u.team_id = t.id " +
"ORDER BY v.created_at DESC",
countQuery = "SELECT COUNT(*) FROM viewing_party v " +
"JOIN users u ON v.user_id = u.id " +
"JOIN team t ON u.team_id = t.id"
, nativeQuery = true)
Page<NativeListDTO> findAllByOrderByCreatedAtDesc(Pageable pageable);
interface NativeListDTO{
Long getId();
String getName();
String getUserName();
String getTeamName();
String getPhotoURL();
String getPartyDate();
Double getLatitude();
Double getLongitude();
String getLocation();
String getShortLocation();
}좀 많이 복잡하다만,,, 성능은 확실하다. 우선 왜 저렇게 작성했는지 살펴보자.
- nativeQuery = true : 기존 JPQL을 사용하는 것이 아니라, DB에서 사용되는 원형의 쿼리를 사용한다.
- value : 쿼리 작성
- countQuery : 페이징을 위해서 필요한 옵션이다. Pageable로 호출하는 page와, size에 대해 계산할 수 있게 쿼리 결과에 대해 전체 크기를 알려줘야한다.
- interface NativeListDTO : 네이티브 쿼리는 DB에서 반환된 각 칼럼 값을 이름으로 식별하고, 이를 DTO의 필드에 매핑한다. 이때 인터페이스의 getter 메서드 이름이 칼럼명과 일치하면 JPA가 이 이름을 기준으로 결과를 매핑할 수 있다.
- 예를 들어, AS userName이라고 쿼리에서 지정하면, 인터페이스에서도 getUserName()이라는 getter가 있어야 JPA가 이를 찾아서 값을 할당할 수 있다.
테스트
부하 테스트 툴은 Jmeter를 사용했다.
- 초당 동시 트래픽 200명
- 샘플링 대략 2000명
요약본


초당 트랜잭션 실행 수


응답 시간

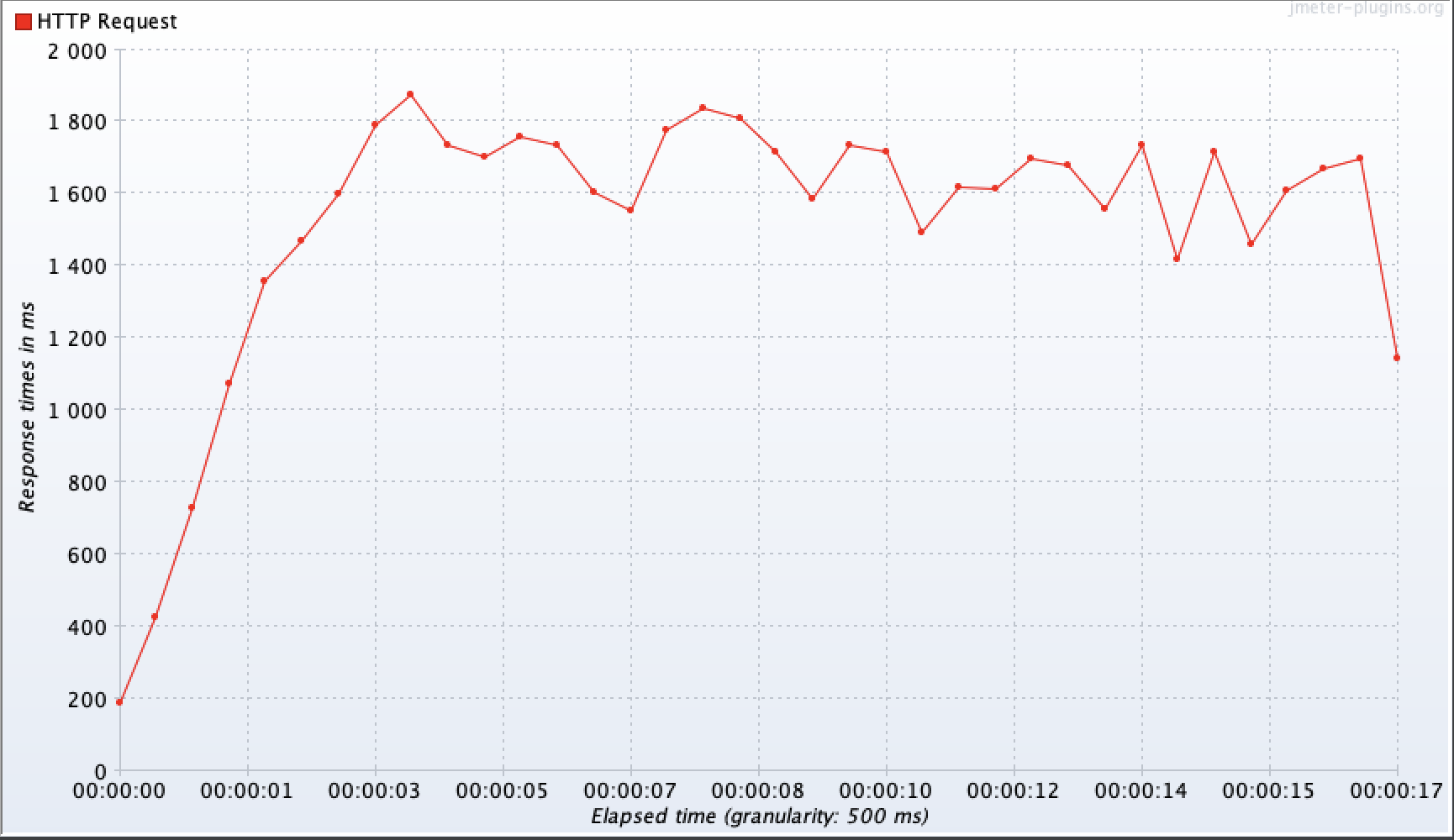
- 모든 측정에서 DTO로 Projection 했을 경우 2배 이상 향상된 성능을 보여준다!
- 연관관계가 복잡하게 얽혀있고, Get Method를 통해 조회만을 할때 이런식으로 활용하면 좋을 것 같다!